Minikube Nesir? Minikube, Kubernetes projesi için hizmet veren bir altyapı ürünüdür. Geliştiriciler için local bilgisayarlarda single node bir cluster kurulumu sağlar. Komutlar aracışılığı ile bir cluster ayağa kaldırıp durdurulabilmektedir. Locaol ortamda kurulum için Docker, QEMU, Hyperkit, Hyper-V, KVM, Parallels, Podman, VirtualBox gibi platformlar üzerinde cluster ayağa kaldırmak için seçenekler sunar.
Kubernetes cluster, AWS, Azure, Google Cloud v.b gibi ortamlarda ücretli olarak kurulup yönetilebilien bir üründür. Geliştirme sırasında local ortamlarda kurulup denemeler yapılabilen bir ortam ihtiyacı gerekmektedir. Bu noktada ilk akla gelen kurulumlardan biri minikube olmaktadır. Minikube kurulumu burada anlatılmaktadır.
Kurulum sonrasında Minikube bir Kubernetes cluster ayağa kaldırmak için kullanıcıdan parametre olarak bir platform belirtmesini ister. Belirtilmez ise, sistemde öncelikli olarak bir docker platformu arar. Bulamaz ise sırayla Hyperkit, KVM gibi yukarıdaki platformların olup olmadığını kontrol eder ve bulduğu ortamda bir cluster ayağa kaldırır.
Linux işletim sistemi üzerinde brew aracı ile kurlum aşağıdaki komut ile yapılabilmektedir. Aşağıdaki örnekler windows 10 üzerinde kurulu WSL ubuntu komut satırından verilmiştir.
brew install minikube
Single Node Cluster
Kurulum sonrasında minikube cluster için aşağıdaki komutlar çalıştırılır.
Eğer docker üzerinde standart single node bir cluster kurulum istenirse:
minikube start
Eğer sistem üzerindeki hyper-v üzerinde standart single node bir cluster kurulum istenirse:
minikube start --driver=hyper-v
Komut ile cluster oluşturulur ve kubectl aracı, minikube cluster kullanımı için yapılandırılır.
Sitemde birden fazla kubernetes cluster context tanımlı ise bunlar arasında kubectl aracı ile geçiş sağlanabilir. Örneğin sistemde google kubernetes engine (GKE) kurulu ise, bu context üzerine geçiş için aşağıdaki komut kullanılır.
Minikube durumunu kontrol etmek için kontrol komutu.
minikube status
Oluşturulan kuebrnetes node’u görüntülemek için aşağıdaki komut kullanılır.
Multiple Node Cluster
Minikube üzerinde birden fazla node ile kubernetes cluster oluşturmak mümkündür.
minikube start --nodes 2 -p multinode
2 node dan oluşan bir cluster ayağa kaldırılır ve kubeclt aracı, multinode isimli yeni contex üzerinde çalışacak şekilde ayarlanır.
Normalde minikube default profil olarak “minikube” isimli profili arar. Dolayısıyla Multinode oluşturduktan sonra “minikube profile” komutu aşağıdaki gibi cevap vermez.
Bu durumda profil değişikliği yapılmalıdır.
Node kontrolü sonrasında iki node oluştuğu görünebilir.
Cluster Durdurma ve Kaldırma
Kubernetes cluster durdurmak ve tekrar çalıştırmak için gerekli komutlar:
Kafka, dağıtık mimari ile tasarlanmış bir mesajlaşma sistemidir (Distributed Messaging System). LinkedIn tarafından 2010 yılında geliştirilmeye başlanan projedir. 2011 yılında, Apache Software Foundation aracılığıyla açık kaynaklı bir yazılım haline getirildi ve yazılım dünyasına, gerçek zamanlı (realtime) veri akışlarını (stream) yönetmek için güçlü bir çözüm sunulmuş oldu.
Kafka sağladığı hız avantajı ile büyük ölçekli mesajlaşma uygulamalarında veya streaming uygulamalarında kullanım tercihinde ilk sırada yer alır. Streaming servislerde tercih edilmesinin sebebi kuyruktaki mesajların diskte kalıcı olarak saklanmasıdır. Amazon AWS üzerinde 1-2 CPU ve 4 GB RAM ile saniyede 135000 mesaj yazma işlemi burada test edilmiştir. İyi yapılandırılmış bir Kafka cluster üzerine saniyede iki milyon mesaj yazılabilmektedir.
Kafka Temel Özellikleri
Bir sistem için mesaj üretenler ile bu mesajları tüketenleri birbirinden ayırmak. Mesaj üreten uygulamalar Producer ve tüketen uygulamalar Consumer olarak adlandırılır. Producer uygulamalar mesajları yayınlama (Publish) yöntemi ile sisteme bırakırken, Consumer uygulamalar sisteme abone (Subscribe) olarak mesajları alırlar.
Mesaj akışları gerçek zamanlı (realtime) olarak işlenebilir.
Sistem, dağıtık mimari tasarımı sayesinde yatak olarak büyüyebilmektedir. Birden fazla sunucu (broker) bir araya gelerek küme (cluster) mantığında organize bir şekilde çalışabilmektedir.
Sisteme kaydedilen veriler değiştirilemez özellikte olup diskte kalıcı olarak tutulur. Bu düzen, veri tabanlarındaki commit log yapısına benzer. Log yapısının özelliği, log dosyalarına yazılan kayıtların daha sonra değiştirilmemesidir. Dosyaya sadece yeni satırlar eklenir.
Kafka Topic, Partition, Offset Bileşenleri
Kafka ile veri işleme sırasında kullanılan temel bileşenler Topic, Partition, Offset şeklinde sıralanabilir.
Kafka Topic
Mesajların bir veya birden fazla gruba bölünmüş (partitioned) halde tutulduğu yerdir. Verilerin birbirinden ayrılmasını sağlayan mantıksal gruplardır. Veri tabanı tabloları veya işletim sistemindeki klasörler gibi düşünülebilir. Bir Topic, birden fazla Kafka broker (sunucu) üzerinde dağıtık bir şekilde tutulabilir. Bu sayede ölçeklendirme sağlanarak, bir broker kapandığında veri kaybı yaşanmadan diğer broker üzerinden veri erişimi devam eder.
Kafka Partition
Sürekli olarak mesaj eklenen sıralı, değişmez bir mesaj dizisidir. Bir topic bir veya daha fazla partition’dan oluşabilir. Bir partition, broker veya diskler arasında bölünemezler, bitişik olmalıdır. Ancak bir topic iki sunucuya dağıtıldığında iki farklı sunucuda partition’lar yine bütün olarak dağılmış olur. Yani Partition1 için ilk N veri A sunucusunda, geri kalanı B sunucusunda olamaz. Partition1 bütün olarak iki sunucuda aynı topic adı altında bulunur.
Gönderilen mesajlarda bir anahtar (key) değeri verilmediğinde, round robin algoritmasına göre mesajlar sırayla her partition içerisine yerleştirilir.
Partition ile verileri gruplar halinde tutabilmek mümkündür. Örneğin customers topic ile müşteri bilgilerinin tutulsun. Müşterilerin kimlik numarasının son hanesine göre P0,P1,…P9 şeklinde 10 partition oluşturularak kaydedilebilir. Bu durumda partition içerisindeki veri sayıları aynı olmaz.
Consumer uygulaması hangi partition içerisinden veri alacağı ile ilgilenmez. Doğrudan subscribe olarak verileri alabilir. Partition’lar sisteme bağlanan consumer veya consumer gruplara otomatik olarak atanır. Örneğin 3 partition bulunan bir topic’e bağlanan A grubunda tek bir consumer var ise üç partition’a gelen veri doğrudan bu consumer tarafından tüketilir. B grubunda iki consumer olduğunu var sayalım. Bu durumda iki partition bir consumer’a kalan bir partition ise diğer consumer’a yönlendirilir. C grubunda üç adet consumer var ise topic’deki her partition verisi gruptaki bir consumer’a yönlendirilir.
Kafka Offset
Partition içerisindeki mesajlara, her mesajı benzersiz şekilde tanımlayan, ofset adı verilen sıralı bir kimlik numarası atanır. Bu bilgi offset topic içerisinde tutulur. Offset bilgisi, topic içerisindeki bilgileri okumak için bağlanan Consumer uygulaması, her veri okuduğunda bir artırılarak uygulamanın sıradaki okunacak mesaj indeksini tutar. Bu sayede Consumer kapanıp tekrar açıldığında verileri en baştan almaz.
Kafka topic mesajlarının silinmesi
Kafka sisteminde okunan mesajlar hemen silinmez. Mesaj sone erme süresi boyunca tutulduktan sonra otomatik olarak silinir.
Kafka sisteminde mesaj silmenin üç farklı yöntemi vardır.
Mesaj Expiry süresine göre silme. Bu süre Kafka üzerinde topic oluşturulurken retention.ms olarak ayarlanabilmektedir. Kafka’nın performansı, veri boyutundan etkilenmez, bu nedenle çok sayıda veriyi saklamak sorun olmaz.
Kayıt silme yöntemi ile kayıtlar doğrudan silinebilmektedir. kafka-delete-records.sh aracı ile kayıtlar doğrudan silinebilmektedir.
Docker sanallaştırma sistemi, varsayılan ayarlarda 172.17.0.0/12 ağlarını kullanır. Sistemde bu ağlardaki adresleri kullanan başka cihazlar (sunucu, bilgisayar vs.) varsa Docker ayarlarını değiştirebilirsiniz. Bu durumda, olası ağ çakışmalarını önlenebilir. Örneğin 172.21.122.23 adresinde çalışan bir varitabanı sunucusu varsa ve kendi bilgisayarınız bu sunucuya ulaşabildiği halde docker container erişemiyorsa, bu durumda çakışma olma ihtimali yüksektir.
Docker mevcut ağ ayarlarının görüntülenmesi
Docker üzerinde hangi ağların kullanıldığını öğrenmek için aşağıdaki komut kullanılır:
docker network list
Komut çıktısında NAME sütunu, kullanılan ağların adlarını gösterir.
NETWORK ID NAME DRIVER SCOPE
24a38927e118 bridge bridge local
b92a38ed491b elk_net bridge local
1d9237551d88 microservice bridge local
f57c6099ef24 host host local
dbb6fb4096c5 none null local
Kullanılan adres alanı (address space) hakkında bilgi almak için aşağıdaki komut kullanılır.
Dotnet core veya .Net Framework uygulamalarında bir Web servisine erişmek için HttpClient sınıfından bir nesne oluşturulur ve kullanılır. Buraya kadar her şey normal. İşlem bittikten sonra kullanılan bu nesne yok edilir. İşte bu durumda işler biraz karışmaya başlar.
HttiClinet using blok ile kullanımı
public class ToDoClient : IToDoClient
{
public async Task<Todo> Get(int id)
{
using(var client = new HttpClient())
{
BaseAddress = new Uri(
"https://jsonplaceholder.typicode.com");
}
return await client.GetFromAsync<ToDo>(
$"/todos/{id}");
}
}
HttpClient sınıfı, IDisposible interface uyguladığı için, using bloğu ile kullanılabilir. Using bloğunda oluşturulan nesneler, blok sonunda ortadan kaldırılır. Ancak nesnenin kullandığı soket hemen serbest bırakılmaz. Ağır yük altında kullanılabilir soket sayısı azalır hatta tükenebilir. Burada konu ile ilgili bir yazı bulunmaktadır.
Yeniden kullanılabilir HttpClient nesnesi
Bu durumun önüne geçmek için tek bir kez singleton olarak oluşturulan ve paylaşılan bir HttpClient nesnesi kullanılabilir.
public class ToDoClient : IToDoClient
{
private readonly HttpClient client = new ()
{
BaseAddress = new Uri(
"https://jsonplaceholder.typicode.com");
};
public async Task<Todo> Get(int id)
{
return await client.GetFromAsync<ToDo>(
$"/todos/{id}");
}
}
Bu çözüm ise, az sayıda kullanılan kısa ömürlü console uygulamaları için uygun olabilir. Ancak geliştiricilerin karşılaştığı diğer bir sorun, uzun süren işlemlerde paylaşılan bir HttpClient örneği kullanırken ortaya çıkar. HttpClient’in tekil veya statik bir nesne olarak başlatıldığı bir durumda, DNS ip değişiklikleri yapılırsa uygulama hata alır. Örneğin load balancer ile bir DNS birden fazla ip de bulunan sunuculara sırayla yönlendiriliyor olabilir.
Bu arada ToDoClient Program.cs içerisinde singleton olarak tanımlanabilir. Eğer Transient veya Scoped olarak kullanılırsa her request sırasında yeniden nesne oluşturacaktır. Bu durumun önüne geçmek için HttpCleint nesnesi static olarak tanımlanabilir.
public class ToDoClient : IToDoClient
{
private static readonly HttpClient client = new ()
{
BaseAddress = new Uri(
"https://jsonplaceholder.typicode.com");
};
public async Task<Todo> Get(int id)
{
return await client.GetFromAsync<ToDo>(
$"/todos/{id}");
}
}
Ancak bu durumda BaseAddress ile tanımlanan DNS TTL süresi bittiğinde domain adı yeni bir ip adresini işaret eder. Ancak kod restart olmadan yeni ip adresini bilemez. Çünkü default HttpClient içerisinde bunu yakalayan bir mekanizma bulunmaz. Bu durumun yakalayabilmek için SockeHttpHandler kullanılabilir.
public class ToDoClient : IToDoClient
{
private SocketsHttpHandler socketHandler = new()
{
PooledConnectionLifetime = TimeSpan.FromMinutes(5)
};
private static readonly HttpClient client = new (socketHandler)
{
BaseAddress = new Uri(
"https://jsonplaceholder.typicode.com");
};
public async Task<Todo> Get(int id)
{
return await client.GetFromAsync<ToDo>(
$"/todos/{id}");
}
}
Ancak bu yöntem de en iyi çözüm yolu değildir. En iyi çözüm yolu .NET Core 2.1 ile birlikte gelen IHttpClientFactory interface kullanmaktır.
IHttpClientFactory Kullanımı
Bu interface kullanmadan önce Program.cs içerisinde bir tanımlama yapılması gerekmektedir.
Bu düzenleme ile artık HttpClient aşağıdaki gibi kullanılabilir.
public class ToDoClient : IToDoClient
{
private readonly HttpClient _httpClient;
public ToDoClient(HttpClient httpClient)
{
_httpClient = httpClient;
}
public async Task<Todo> Get(int id)
{
return await _httpClient.GetFromAsync<ToDo>(
$"/todos/{id}");
}
}
Bu durumda HttpClient nesnesi IHttpClientFactory tarafından yönetilmektedir. Çünkü ortak bir havuzdaki HttpMessageHandler nesneleri, birden çok HttpClient örneği tarafından yeniden kullanılabilen nesnelerdir. Bu sayede DNS sorunu çözülmektedir.
Named Client kullanımı
Servis binding sırasında AddHttpClient() metoduna bir isim vererk kullanmak mümkündür.
Microsoft .net core 6 bazı yenilikleri de beraberinde getirdi. Yeni bir proje oluşturulduğunda karşımıza çıkan ilk yenilik minimal asp.net uygulaması olacaktır. Asp.net core 6 ile Program ve Starup class sınıfları kaldırılarak minimal api dünyasına giriş yapılmıştır.
Minimal şablonda Program ve Startup class’lar bulunmaz. Program.cs içerisinde class bulunmayan düz bir yapı bulunur.
Konfigurasyonun oluşturulabilmesi için yeni bir WebApplicationBuilderAPI bulunu.
var builder = WebApplication.CreateBuilder(args);
var app = builder.Build();
app.MapGet("/", () => "Hello World!");
app.Run();
Uygulamaya ait bütün ayarlar bu dosya içerisinde yapılandırıldığından Serilog ayarları da burada konumlandırılır. (.Net Core 6 konfigürasyon ayarları.)
Neden Serilog Kullanılır?
Bir .net 6 uygulamasında üretilen log’ların bir çok farklı yere akması (sink) istenebilir. Örneğin konsol, metin dosyası, SqlServer, Oracle, Elasticsearch, Kafka, Redis, vs. gibi. Serilog altyapısı, geliştiricilere sadece konfigürasyon ayarları ile, kodlama yapısına hiç dokunmadan, log bilgilerini farklı kaynaklara aktarabilme imkanı sağlar.
Uygulamaya Serilog eklenebilmesi için Serilog.AspNetCore paketinin eklenmesi gerekir.
dotnet add package Serilog.AspNetCore
veya
NuGet\Install-Package Serilog.AspNetCor
Örneğin Apache Kafka’ya log yazabilmek için Serilog.Sinks.Kafka nuget paketinin uygulamaya eklenmesi gerekir.
.Net Core 6 da Serilog Kullanımı
Bir önceki .Net 5 versiyonunda serilog implementasyonu aşağıdaki gibidir.
using Serilog;
var builder = WebApplication.CreateBuilder(args)
.UseSerilog(...);
// Error CS1929 : 'WebApplicationBuilder' does not contain a definition for 'UseSerilog' and
// the best extension method overload 'SerilogWebHostBuilderExtensions.UseSerilog(
// IWebHostBuilder, ILogger, bool, LoggerProviderCollection)' requires a receiver of type
// 'IWebHostBuilder'
Bu uygulanış şekli .net 6 versiyonunda değişmiştir. Bu nedenle yukarıdaki hata mesajı alınacaktır. Doğru uygulama şekli aşağıdaki gibidir.
IHostBuilder içerisinde bulunan builder.Host kullanılır.
var builder = WebApplication.CreateBuilder(args);
builder.Host.UseSerilog((builderContext, loggerConfiguration) => loggerConfiguration
.WriteTo.Console()
.WriteTo.Kafka());
var app = builder.Build();
Bu şekilde yapılandırma ile hem konsol hem de Kafka’ya log akması sağlanabilir. Bu şekilde düzenlenen Serilog yapılandırmasında, ayarlar kod tarafında verilir. Örneğin Kafka sunu ayarları değiştiğinde aşağıdaki gibi düzenleme yapılır.
var builder = WebApplication.CreateBuilder(args);
builder.Host.UseSerilog((builderContext, loggerConfiguration) => loggerConfiguration
.WriteTo.Console()
.WriteTo.Kafka("MyTopicName", "172.15.45.3:9092"));
var app = builder.Build();
Konfigürasyonun appsettings.json üzerinde yapılması
Serilog ayarları appsettings.json dosyası içerisinde Serilog section içerisinde yapılandırıldığında, kod tarafında bir değişiklik yapmaya gerek kalmaz.
Bu konfigurasyonun okunabilmesi için kod tarafında bir değişiklik gerekir.
var builder = WebApplication.CreateBuilder(args);
builder.Host.UseSerilog((builderContext, loggerConfiguration) => loggerConfiguration
.ReadFrom.Configuration(builderContext.Configuration));
var app = builder.Build();
Burada dikkat edilmesi gereken noktalardan biri, eğer MinimumLevel bölümündeki Override bölümünde bulunan Microsoft veya System kategorileri aşağıdaki gibi Warning veya Error gibi seviyelere çekilirse, geliştirme aşamasında üretilen Information logları akmaz. Bu durumda uygulamanın çalışmadığı hissine kapılmamak gerekir.
Bu ayarlamaya göre, MinimumLevel olarak Debug seviyesinde oluşan log bilgileri akar. Override kısmında hangi kategoriye göre hangi seviyede log akışı olacağı bilgileri yer almaktadır. Bilindiği gibi .net core ile sınıflar içerisinde log bilgilerini yazmak için ILogget<TCategoryName>interface kullanılır. Örneğin:
public CategoryController(ILogger<CategoryController> logger)
{
logger.LogInformation("CategoryController started.");
logger.LogError("Error!");
}
TCategryName log kullanan ilgili sınıfın (CategoryController) ismidir. Fakat log işlemlerinde arka planda bu sınıfın tam ismi kullanılır. Örneğin Shopping.WebApi.Controllers.CategoryController şeklinde tam isim alınır. Nemespace bilgisi Shopping ile başlayan kategori loglarını information seviyesinde akıtmak için Override bölümü aşağıdaki şeklilde düzenlenebilir.
ASP.NET Core’da (6.0 versiyonda) bir uygulamaya dışarıdan bir konfigürasyon ayarı, bir veya daha fazla configuration provider kullanılarak gerçekleştirilebilir. Provider diye adlandırılan araçlar, appsettings.json dosyaları veya environment variables gibi çeşitli yapılandırma kaynaklarını kullanarak konfigürasyon ayar verilerini okurlar.
Uygulamada Configuration ayarları, Program.cs dosyası içerisinde yapılabilir. Ayarların değerleri ise appsettings.json dosyası içerisinde bulunur. Örneğin aşağıdaki appsettings.json içerisinde Connection isimli bir section oluşturulmuştur.
Connection ayarlarını uygulama içerisinde kullanmanın birden fazla yolu vardır. Bunlar aşağıda başlıklar halinde belirtilmiştir.
IConfiguration interface ile erişim
Bir class içerisinden Connection section ayarlarına erişmek için IConfiguration interface kullanılabilir. Bu interface, Microsoft.Extensions.Configuration içerisinde bulunur ve dependency injection ile istenen class içerisinden erişilebilir.
public class DatabaseService
{
private readonly string _host;
private readonly int _port;
public DatabaseService(IConfiguration config)
{
_redisHost = config["Connection:Host"];
_redisPort = Convert.ToInt32(config["Connection:Port"]);
}
}
Ancak bu yöntem ile her Configuration ihtiyacı sırasında, class içerisinde section isimleri, değer isimleri ve casting işlemleri yapılmak zorundadır.
İşi bir adım daha ileriye taşıyabilmek adına, ilgili configuration section, bir nesneye dönüştürülebilir.
ConnectionOptions class:
public class ConnectionOptions
{
public const string SectionName = "Connection";
public string Host{ get; set; } = String.Empty;
public string Port { get; set; } = String.Empty;
}
Options pattern ile erişim
Configuration için bir nesne tanımlandıktan sonra, ilgili class içerisinde kullanım şekli aşağıdaki gibi değiştirilebilir.
public class DatabaseService
{
private readonly ConnectionOptions options;
public DatabaseService(IConfiguration config)
{
options = new ConnectionOptions();
config.GetSection(ConnectionOptions.SectionName)
.Bind(options);
}
}
Alternatif bir yol olarak ise aşağıdaki kullanım da tercih edilebilir.
public class DatabaseService
{
private readonly ConnectionOptions options;
public DatabaseService(IConfiguration config)
{
options = config.GetSection(ConnectionOptions.SectionName)
.Get<ConnectionOptions>();
}
}
Options pattern kullanırken en yaygın yöntem, servis binding işlemlerinin kullanıcı class içerisinde değil de aşağıdaki gibi Program.cs içerisinde yapılmasıdır.
Options pattern IOptions<T> interface ile erişim
Configuration binding ayarlarını, tek bir extension method içerisine alarak Program.cs içeriği sadeleştirilebilir. Bu amaçla, aşağıda bir extension method tanımlanmıştır.
public static class ConfigServiceCollectionExtensions
{
public static IServiceCollection AddConfig(
this IServiceCollection services,
IConfiguration config)
{
services.Configure<ConnectionOptions>(
config.GetSection(
ConnectionOptions.SectionName));
return services;
}
}
Program.cs aşağıdaki gibi düzenlenebilir.
using ConfigSample.Options;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddConfig(builder.Configuration);
var app = builder.Build();
Bu durumda DatabaseService class içeriği aşağıdaki şekilde değiştirilebilir.
public class DatabaseService
{
private readonly ConnectionOptions options;
public DatabaseService(IOptions<ConnectionOptions> options)
{
options = options.Value;
}
}
Configuration section class’a dependency injection ile erişim
Bir Microsoft extension tipi olan IOptions<T> tipini kullanmadan, DatabaseService içerisine doğrudan ConnectionOptions tipi dependency injection yöntemi ile verilebilir. Bunun için öncelikle ConfigServiceCollectionExtensions sınıfı içerisinde küçük bir değişiklik yapılmalıdır. İki farklı alternatif ile singleton olarak ConnectionOptions tipine binding sağlayabiliriz.
ConfigServiceCollectionExtensions Seçenek-1
public static class ConfigServiceCollectionExtensions
{
public static IServiceCollection AddConfig(
this IServiceCollection services,
IConfiguration config)
{
services.Configure<ConnectionOptions>(
config.GetSection(
ConnectionOptions.SectionName));
services.AddSingleton(options =>
options =>
GetService<IOptions<ConnectionOptions>>().Value);
return services;
}
}
ConfigServiceCollectionExtensions Seçenek-2
public static class ConfigServiceCollectionExtensions
{
public static IServiceCollection AddConfig(
this IServiceCollection services,
IConfiguration config)
{
ConnectionOptions options = new();
config.GetSection(ConnectionOptions.SectionName)
.Bind(options);
services.AddSingleton(options);
return services;
}
}
Bu durumda, DatabaseService içeriği aşağıdaki gibi yeniden düzenlenebilir. (Program.cs de hiç bir değişikliğe gerek yoktur, yukarıdaki ayarlar geçerlidir.)
public class DatabaseService
{
private readonly ConnectionOptions options;
public DatabaseService(ConnectionOptions options)
{
options = options;
}
}
Artık servis sınıfı içerisinde Microsoft options pattern tipleri yerine, kendi sınıflarımızı kullanabilir hale getirmiş olduk.
Git günümüzde oldukça popüler bir sürüm kontrol sistemidir. Bu yazıda, master branch üzerinde yapılmış ancak henüz commit edilmemiş değişikliklerin yeni bir branch üzerine nasıl taşınacağını inceleyeceğiz. Git hakkında temel bilgiler için buradan faydalanabilirsiniz.
Git projesine yeni özellik eklenmesi
Git tarafından yönetilen bir projeye yeni bir özellik eklerken kullanılan genel akışı şu şekildedir.
Yeni bir “feature/development” benzeri isimde branch oluşturulur, ardından o branch’e geçilir.
Geliştirme tamamlanır ve local repository üzerinde commit edilir.
Feature branch (feature/development) remote repository üzerine push edilir ve pull request oluşturulur.
Pull request, takım üyeleri tarafından incelendikten sonra yeni değişiklikler master branch veya yayın yapılacak olan branch ile birleştirilir.
Problem
Bazen değişiklikler yapmaya başlarız fakat yeni bir feature branch oluşturmayı ve buna geçmeyi unutabiliriz. Sonuç olarak, değişikliklerimizi gerçekleştireceğimiz zaman, yanlış branch üzerinde olduğumuzu fark edebiliriz. Örneğin bütün değişiklikleri master branch üzerinde yaptığımızı fark edebiliriz. Çoğu zaman remote master branch, üzerine doğrudan commit edilemeyecek şekilde yapılandırılır. Bu nedenle yeni bir feature branch oluşturmamız ve commit edilmeyen işleri yeni branch üzerine taşımamız gerekir. Burada önemli olan nokta, ana branch üzerinde bir değişikliğin yapılmamasıdır.
Örnek bir senaryoyu aşağıdaki adımlarla inceleyebiliriz. Branch durumlarını görüntülemek için komutlar aşağıdaki gibidir.
$ git branch
* master
$ git status
On branch master
nothing to commit, working tree clean
Yukarıdaki çıktıdan da görebileceğimiz gibi, şu anda master branch üzerindeyiz ve temiz bir branch olduğu görünüyor.
Projemize login.html diye bir dosya ekleyerek değişiklikleri izleyecek olursak:
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
login.html
nothing added to commit but untracked files present (use "git add" to track)
Yukarıdaki çıktının gösterdiği gibi, yeni bir login.html dosyası eklendi. Şimdi tam bu anda, işin master branch yerine bir fature branch üzerine eklenmesi gerektiğini fark ediyoruz.
Git yeni branch oluşturma
Yeni bir brach oluşturmak için git checkout <BranchName> komutu kullanılır. Yeni brach oluşturup oluşturulan brach’e geçiş yapmak için git checkout -b <BranchName> komutu kullanılır. Ayrıca, bu komut mevcut branch’i olduğu gibi bırakacak ve tüm commit edilmemiş değişiklikleri yeni branch üzerine getirecektir.
$ git checkout -b feature/login
Switched to a new branch 'feature/login'
$ git status
On branch feature/login
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
login.html
nothing added to commit but untracked files present (use "git add" to track)
Yukarıdaki komutlardan anlaşıldığı gibi, feature/login isimli branch oluşturuldu ve commit edilmeyen tüm değişiklikler master branch üzerinden dan feature/login branch üzerine taşındı. Artık, değişikliklere stage ve commit işlemleri uygulanabilir. İki işlemi bir arada yapan komutlar aşağıdaki gibidir.
Şimdi master branch üzerinde onu değiştirmeden bıraktığımızdan emin olmalıyız.
$ git checkout master
Switched to branch 'master'
$ git status
On branch master
nothing to commit, working tree clean
Master branch üzerinde her hangi bir değişiklik olmadığı görülüyor.
İşler yeni branch üzerinde commit edildiğinden dolay bu branch (feature/login) remote repository’ye aktarılabilir.
$ git push -u origin feature/login
Remote repository üzerinde değişiklikler yine feature/login branch üzerinde oluşturulmuştur. Artık remote repository de, pull request ile değişiklikler master branch üzerinde birleştirilebilir. Birleştirme işleminden sonra local repository üzerinde master branch’e geçilerek pull işlemi ile master branch güncellenir.
Web uygulama mimarileri, uygulamanın nasıl geliştirildiğinden, nasıl yayına alındığına kadar planlanan adımlar dizisidir. Günümüzde bir çok uygulama, IIS, Tomcat veya Nginx gibi ortamlarda tek bir application domain altında tek bir birimden oluşmuş şekilde çalışabildiği gibi, birden fazla application domaine hatta birden fazla sunucuya dağıtılmış şekilde çalışabilen uygulamalar mevcuttur. Bununla birlikte, tek bir dağıtım birimi ile deploy edilip çalışan uygulamalar bile, mantıksal olarak birkaç katmana ayrılabilmektedir. Yazılım mühendisliğinin amaçlarından biri de çok sık değişen kod ile az değişen kodu birbirinden ayırmaktır.
Genel olarak kullanılan mimariler Monolitik, N-Katmanlı ve Clean architecture olarak adlandırılabilir.
Monolitik (Tek katmanlı) uygulama nedir?
Monolitik uygulamalar, kullanıcı arayüzü ve veri erişim kodunun tek bir programda birleştirildiği tek katmanlı bir uygulama biçimidir. Uygulamanın sunucu ortamlarında dağıtılması tek bir birim şeklindedir. Böyle bir uygulamanın yatay olarak ölçeklenmesi gerekiyorsa, uygulamanın tamamı birden çok sunucu veya sanal makine arasında çoğaltılır.
Monolitik uygulama mimarisi proje yapısı
Bu uygulama mimarisinde, geliştirilen uygulamanın tüm birimleri tek bir projede tutulur, tek bir derlemede derlenir ve tek bir birim olarak dağıtılır.
Projede iş birimlerinden birbirinden ayrılması, klasörleme mantığına göre yapılır. Örneğin MVC pattern uygulanıyorsa Model, View, Controller, Data gibi klasörlere dağıtılmış bir şekilde geliştirme yapılır. Bu düzenlemede, uygulama görünümü ile ilgili detaylar Views klasörüyle, veri erişim uygulama detayları ise Data klasöründe tutulan sınıflarla sınırlandırılmalıdır. İş mantığı, Models klasöründeki servis ve sınıflarda bulunmalıdır.
Uygulanışı her ne kadar basit olsa da bu mimarinin dezavantajları vardır.
Teknolojik araçlardan veritabanına yazma işlemlerine, arayüz tasarımına kadar her şey tek bir projededir. Böyle bir ortamda aradığını yerli yerinde bulmak zordur.
Projenin boyutu ve karmaşıklığı arttıkça dosya ve klasörlerin sayısı da artar.
Kullanıcı arabirimi (UI) iş parçacıkları (Models, Views, Controller) birden fazla klasöre dağılmıştır.
UI tarafında, filter, model binder, exception partial modeller eklendikçe klasörler büyümeye ve karmaşıklık artmaya devam eder.
Business mantığı Models ve Services klasörleri arasında dağılmış ve hangi klasörlerin hangi sınıflara bağlı olması gerektiğine dair net bir gösterge yoktur.
Bir takım halinde çalışma sırasında birden fazla kişinin aynı dosya üzerinde çalışması gerekir ve çakışmalar artar.
Bu durumda uygulanabilirlik azaldıkça, sorunları daha rahat ele alabilmek için uygulamalar, çok projeli yapılara dönüştürülürler.
N-Katmanlı mimari nedir?
Uygulamaların karmaşıklığı arttıkça, bu karmaşıklığı yönetmenin bir yolu, uygulamayı sorumluluklarına veya iş birimlerine göre ayırmaktır. Bu ayrım, seperation of concerns olarak bilinir. Bu yöntem ile geliştiriciler, bir parçanın nerede geliştirildiğini rahatça karar verebilir ve takım geliştirmesi yapıyorlar ise aradıklarını kolayca bulabilirler. Katmanlı mimarinin bir dizi avantajları vardır.
Uygulama kodu ve işlevsellikler katmanlara bölündüğünden, kodda yeniden kullanılabilirlik arttırılır. Uygulama da DRY ( Don’t Repeat Yourself) ilkesi sağlanmış olur.
Hangi katmanların birbiri ile iletişim kuracağı belirlenerek encapsulation sağlanmış olur. Bir katmanda değişiklik meydana geldiğinde sadece onunla çalışan katman etkilenmelidir. Bu sayede bir değişikliğin uygulamanın tümünü etkilemesi engellenmiş olur.
Katmanlar sayesinde uygulama işlevselliğini değiştirmek kolaylaşır. Örneğin bugün Oracle veritabanı ile çalışan sistem bir süre sonra Postgresql ile çalışma ihtiyacı duyduğunda, data interface ile Postgresql implementasyonu yapan yeni bir sınıf ile kodda çok fazla değişkliğe neden olmadan yeni bir altyapı eklenebilir.
Test edilebilirliği kolaylaştırır. Uygulamanın gerçek veri katmanına veya UI katmanına ait çalışan testler yazmak yerine, bu katmanlar test zamanında isteklere bilinen yanıtlar sağlayan sahte (Moq) uygulamalarla değiştirilebilir
Uygulama katmanları
Bu mimariye göre kullanıcılar uygulamaya User Interface üzerinden istekte bulunurlar. User Interface katmanı ise yalnızca Business Logic katmanı ile iletişim kurar. Business Logic katmanı da Data Access katmanından veri isteği yapar. User interface doğrudan Data Access katmanına erişemez. Business Logic katmanı da doğrudan veriye erişmemelidir, veri talebini Data Access katmanından yapmalıdır. Yani her katmanın kendine ait sorumluluğu bulunur.
N-Katmanlı uygulama mimarisi proje yapısı
Bu mimari her ne kadar tek projeli yapıyı çok projeli hale dönüştürse de bazı dezavantajları vardır.
Derleme zamanı bağımlılıkları (dependencies) yukarıdan aşağıya doğru çalışır. Yeni UI katmanı BLL katmanına, BLL katmanı da DLL katmanına bağlıdır. Bu, genellikle uygulamada en önemli mantığa sahip olan BLL’nin veri erişimi uygulama ayrıntılarına ve hatta bir veritabanının varlığına bağlı olduğu anlamına gelir. Böyle bir mimaride iş mantığını test etmek genellikle zordur ve bir test veritabanı gerektirir.
Deployment tek bir birim olarak yapılır. Bu uygulama enterprise amaçlar için birkaç projeye bölünmüş olsa da, tek bir birim olarak dağıtılır ve istemcileri onunla tek bir web uygulaması olarak etkileşime girerler.
Clean architecture nedir?
N katmanlı mimaride bahsedilen yukarıdan aşağı doğru bir derleme bağımlılığını ortadan kaldırmak için çeşitli çalışmalar yapılmıştır. Dependency Inversion ve Domain Driven Design gibi yaklaşımlar aslında benzer bir mimariye ulaşma eğilimindedirler. Bu mimari yıllar içinde birçok isimle anıldı. İlk isimlerden biri Hexagonal Architecture, ardından Ports-and-Adapters oldu. Son zamanlarda, Onion Architecture veya Clean Architecture olarak anıldı.
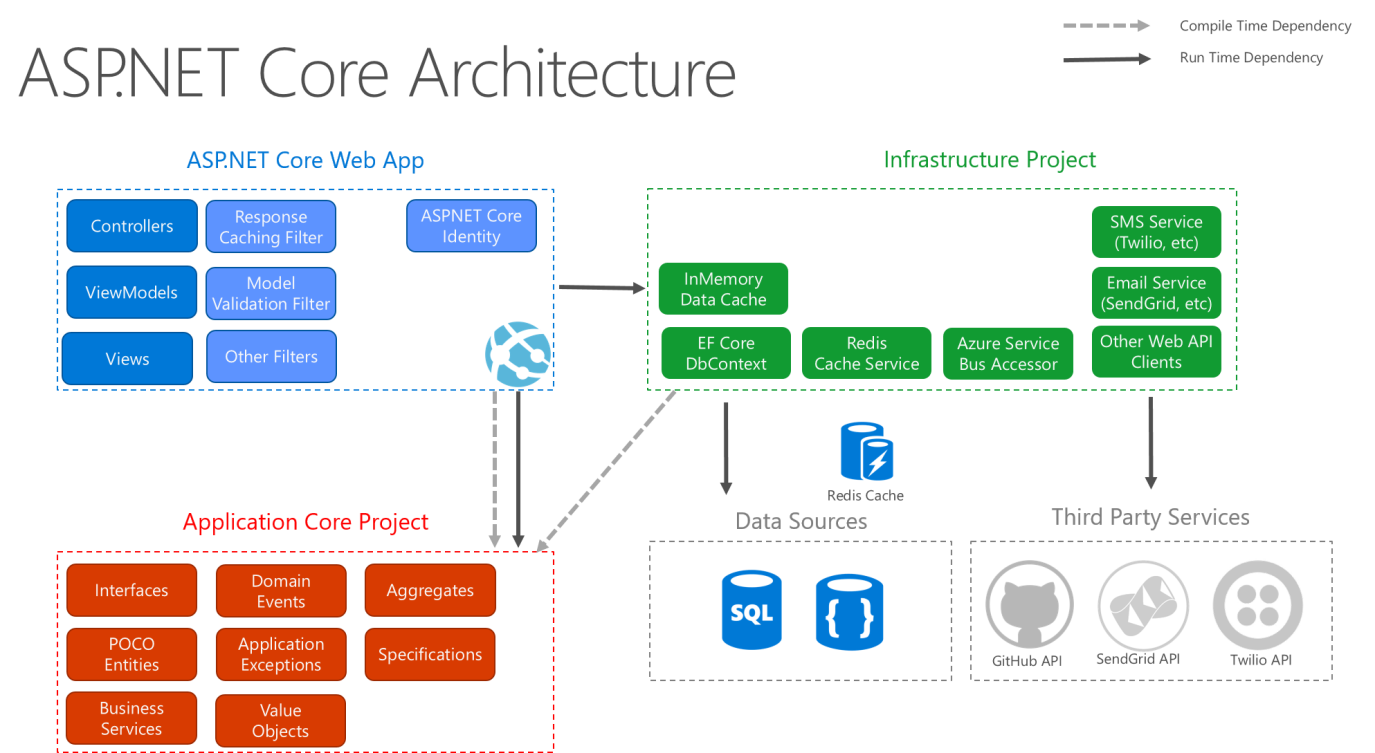
Clean Architecture mimarisi, Business Logic ve Application modelini uygulamanın merkezine (Application Core) koyar. Business Logic veri erişimine veya diğer infrastructure sorunlarına bağlı olması yerine, bu bağımlılık tersine çevrilir: infrastructure ve application ayrıntıları Application Core bağlıdır. Bu işlevselliği sağlamak için Application Core tarafında interface veya abstraction tanımlamaları yapılıp, bu soyut tiplerin implementasyonları da Infrastructure tarafında yapılarak sağlanır. Bu mimariyi görselleştirirken, soğana benzer bir dizi eş merkezli daire kullanmaktır.
Clean Architecture
Bu diyagramda, bağımlılıklar dıştan, en içteki daireye doğru akar. Application Core, adını bu diyagramın merkezindeki konumundan alır. Ve diyagramda, Application Core diğer uygulama katmanlarına bağımlılığı olmadığı görülür. Entity ve Interface tipleri tam merkezdedir. Hemen dışında, ancak yine de Application Core içerisinde, genellikle iç çemberde tanımlanan Interface tiplerini implemente eden domain servisleri bulunur. Application Core dışında, hem UI hem de Infrastructure katmanları, Application Core’a bağlıdır, ancak birbirine bağlı değildir.
Clean Architecture yatay mimari görünümü
Düz okların derleme zamanı bağımlılıklarını, kesikli ok ise yalnızca çalışma zamanı bağımlılığını temsil eder. Clean Architecture ile UI katmanı, derleme zamanında Application Core üzerinde tanımlanan arabirimlerle çalışır ve ideal olarak Infrastructure katmanında tanımlanan uygulama türlerini bilmemelidir. Ancak çalışma zamanında, bu implementasyon türleri uygulamanın yürütülmesi için gereklidir, bu nedenle mevcut olmaları ve bağımlılık ekleme yoluyla Application Core interface tiplerine bağlı olmaları gerekir.
Clean Architecture uygulanan ASP.NET Core uygulaması.
Clean Architecture Katman Yapısı
Katman yapısı oluşturulurken, katmanlara ait projelerin birbirine karışmaması adına öncelikle bir klasör modeli oluşturulabilir.
Daha sonra projeler bu düzene göre kolayca eklenebilir.
Clean Architecture proje yapısı
Presentation
Bu katmanda, kullanıcının uygulama ile iletişim kuracağı ara yüz uygulamaları oluşturulur. Örneğin bir Web Api veya bir desktop uygulama gibi düşünülebilir. Hiç bir katman, en üstte bulunan bu katmana bağımlı olamaz.
Infrastructure
Bu katmanda, uygulamanın dış dünya ile iletişim kurabileceği modüllerin somut implementasyonları yapılır. Örneğin Entity Framework veya NHibernate gibi framework kullanarak veritabanı işlemlerinin gerçekleştirilmesi. Ya da bir SMTP servisine erişerek mail gönderen işlemleri gerçekleştiren sınıfların oluşturulması gibi düşünülebilir.
Core
Bu katmanda Application ve Domain projeleri bulunur.
Domain projesi uygulamanın en soyut ve diğer katmanların hiç birini referans almayan çekirdektir. Entity, Value Objects, Exception ve Enumeration gibi tipleri burada bulunur. Örneğin bir Order entity tipinde, status ve tarih özelliğinin bulunması gibi iş kuralları burada belirlidir.
Application ise uygulama kuralarının belirlendiği projedir. Yani Entity tiplerinin nasıl kullanılacağı burada belirlenir. Application katmanı sadece Domain katmanına bağımlıdır ve oradaki bileşenleri kullanarak iş kuralları oluşturur. Örneğin işimiz ürün satmak ise, sipariş vermek bizim için bir kullanıcı senaryosu olabilir. Bu hizmeti kullanıcıya sunmak için öncelikler ürünün stokta olup olmadığını kontrol etmek ve ardından siparişi oluşturmak gerekir. Bunlar uygulamanın kurallarıdır. Ayrıca uygulamanın interface, abstract gibi business soyutlamaları Application projesinde bulunur. Fakat somut implementasyonları infrastructure katmanında bulunur. Örneğin IProductRepository interface Application projesinde ise, bunu implement eden ProductRepository class Infrastructure projesindedir.
Özet
Tek projeli monolitik yapılar, küçük çaplı ve dağıtık deployment gerektirmeyen proje çözümler için uygundur.
Katmanlı mimari sayesinde tek projeli yapılar birden fazla projeye bölünerek daha yönetilebilir ve takım geliştirmesine uygun hale getirilebilir. Ancak katmanlı mimarilerde core modüllerinin diğer modüllere bağımlılığı oluşmaktadır.
Clean Architecture mimarisi de bu bağımlılığı ortadan kaldırmaktadır. Bağımlılıklar, uygulamanın en önemli parçası olan Application Core katmanına doğru gelişmektedir. Bu sayede katmanlarda test edilebilirlik artar, uygulamanın merkez modülü olan Application Core, soyut bir özellik kazanarak üçüncü parti framework bağımlılıkları ortadan kalkar ve modülü test etmek için her hangi bir database ihtiyacı kalmaz. UI katmanının da aynı şekilde framework ve diğer katmanlar ile sıkı bağı kalmaz. Ancak deployment sırasında uygulamalar bu üç mimaride de bütün olarak deploy edilir.
Not: Uygulamaların önyüz, backend veya feature modüllerini birbirinden ayırarak her birinin ayrı bir servis halinde deploy edilebilmesini sağlayan mimariler, dağıtık mimariler olarak adlandırılır. Dağıtık deploy edilebilen servislerin dağıtık bir şekilde, farklı takımlar ile geliştirilmesi sağlanabilmektedir. Günümüzde dağıtık mimarilerden, özellikle e-ticaret sektöründe en çok tercih edilen mimari, mikro servis mimarisidir. Unutulmamalıdır ki her bir mikroservis özünde monolitik bir uygulamadır. Mikro servisler boyutu küçük olan servisler olarak anlaşılmamalıdır. Tek başına deploy edilebilen servisler olarak anlaşılmalıdır.
Sonuç
İyi mimariler bağımsız modüller yaratmak içindir. İyi yapılandırılmamış bir monolitik uygulama dahi geliştirilemiyorken, probleminize mikroservislerin çözüm olacağını düşünmemek yanlıştır.
Kibana Discover uygulamasında, sorgulamalar belli bir zaman dilimine göre yapılabilmektedir. Bu yazıda Kibana sorgulamalardaki zaman diliminin nasıl yönetildiği incelenmektedir. Aşağıdaki ekran görüntüsünde Kibana Discover uygulamasının arayüzü gösterilmektedir.
Kibna Discover
Bu ekran yardımı ile Kibana sorgu ve filtreleri oluşturularak istenen kayıtlar aranabilmektedir. Takvim kutucuğu yardımıyla aramaları istenen bir tarih aralığında yapabilmek mümkündür.
Discover ekranındaki Inspect penceresinde, Kibana’nın sorguyu dönüştürdüğü Elasticsearch DSL query ifadesi bulunmaktadır. Tarih aralığı seçildikten sonraki sorgu penceresi aşağıdaki gibi olacaktır.
Burada @timestamp alanında, tarih kutucuğundan seçilen tarihlerin -3 saat olarak ayarlandığı görünmektedir. Bunun nedeni, Kibana’nın tarihleri otomatik olarak UTC zaman dilimine çevirmesidir. Tarih formatı sonunda bulunan “Z” harfi, bu saat ifadesinin UTC olduğunu gösterir ve ISO 8601 standardına uygundur.
Kibana tarayıcının zaman dilimini kullanır. Bu nedenle @timestamp alanındaki tarihler tarayıcının zaman diliminden UTC formatına dönüştürülür. Tarih seçimi yapıldığında belirtilen saat, bizim local timezone’umuz olduğundan, UTC dönüşümünde saat farkı oluşmaktadır.
Zaman dilimi farkı
Uluslararası bir şirketin, dünyanın farklı noktalarında bulunan iki ofisinde aynı zaman aralığını seçerek sorgulama yapan kullanıcılar, farklı bölgelerden UTC dönüşümü elde edileceğinden dolayı Elasticsearch sorguları da farklı olacaktır. Bu nedenle aynı sonucu göremeyeceklerdir.
Farklı zaman dilimlerinde yerel saatler
Elasticsearch tarihleri UTC saat diliminde döndürürken Kibana bunları tarayıcımızın saat dilimine göre biçimlendirir.
Şirketin Belçika’da olduğunu ve tarihleri UTC zaman diliminde tuttuğunu varsayalım. Bu durumda İstanbul ve Belçika’da raporlara bakan kullanıcılar aşağıdaki gibi farklı grafik raporlar görecektir.
Durumun farkında olmayanlar, satışların 10-12 veya 9-11 arasında arttığının ayrımını anlayamazlar. Bu da yanlış kararlar verilmesine neden olabilir.
Kibana timezone ayarları
Kibana timezone ayarları, ana menü seçeneklerinden Stack Management seçiminden sonra açılan uygulamanın Advenced Settings bölümünde bulunur.
Bu ayarlardan Time Zone, varsayılan olarak Browser seçilmiştir. Bunu UTC olarak ayarlayabiliriz. Day of week ise Monday olarak seçilebilir.
Bu durumda sorgunun nasıl değiştiğini görebiliriz.
Sorguda artık local timezone dönüşümü yapılmamaktadır.